URLScan - Parsing for Gold
It’s no secret that Urlscan.io can provide valuable target recon information, sometimes even too much information. And, with the ever growing popularity and number of modules for the template-based scanning tool, Nuclei, the importance of reliable site traffic sources has surged, especially so for bug bounty hunters and penetration testers. Urlscan stands out as an exceptional service for recon, and offering an API for both searching and submitting scans.
URLScan.io is used by popular recon tools such as Amass for domain enumeration and GAU for url harvesting.
However, when faced with a target domain with more than 500 results, pinpointing sensitive URLs can be daunting. I spent more time than I should have working through large search responses. This prompted me to develop the scripts outlined below, which have saved me quite a bit of time. If your target domain yields fewer than 500 entries, it’s more efficient to review the entries manually, either through the Urlscan.io search or using GAU.
A typical search query might look like page.domain:(targetdomain.com). A more verbose alternative is domain:(targetdomain.com) but this will also include redirect URLs, potentially taking you out of your intended scope. For clarity, the scripts provided here exclusively utilize page.domain.
The fetch.py and scan.py scripts are located here: https://github.com/Moopinger/URLScanScripts
fetch.py
Firstly, you are going to need an API key from Urlscan.io. This is quick and straightforward: register at https://urlscan.io/user/signup to get one.
After obtaining your API key, insert the value into fetch.py:
...
import time
import sys
#ADD YOUR API KEY HERE
api_key = "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
...Now go ahead and run it:
python3 fetch.py -h
usage: fetch.py [-h] [-domain DOMAIN] [-file FILE] [-output OUTPUT]
Urlscan.io grab results - Moopinger
optional arguments:
-h, --help show this help message and exit
-domain DOMAIN (-d) Domain to fetch urlscan results for eg. test.com
-file FILE (-f) Files containing domains to fetch
-output OUTPUT (-o) Directory to place json results file (default is working dir)Run against mozilla.com:
> python3 fetch.py -d mozilla.com
Starting against mozilla.com : [1 / 1]
[+]Fetched 500 out of 7141
...
[+]Fetched 7141 out of 7141This action will archive the JSON search results in the results directory. You can then process these results with scan.py.
scan.py
> python3 scan.py
usage: scan.py [-h] [-f FILE] [-m MODE] [--no-color]
Urlscan.io json parser - Moopinger
optional arguments:
-h, --help show this help message and exit
-f FILE, --file FILE JSON File generated by fetch.py - contains the Urlscan.io JSON search results
-m MODE, --mode MODE Either "scan", "list" or "info"
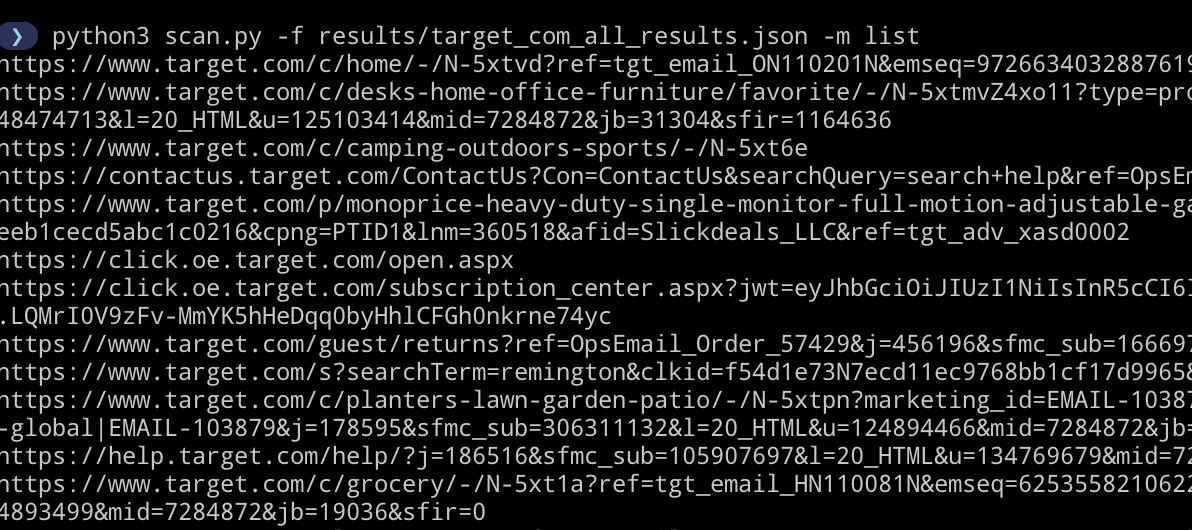
--no-color Suppress color codes-m list
> python3 scan.py -f results/mozilla_com_all_results.json -m list against our previously generated search file:
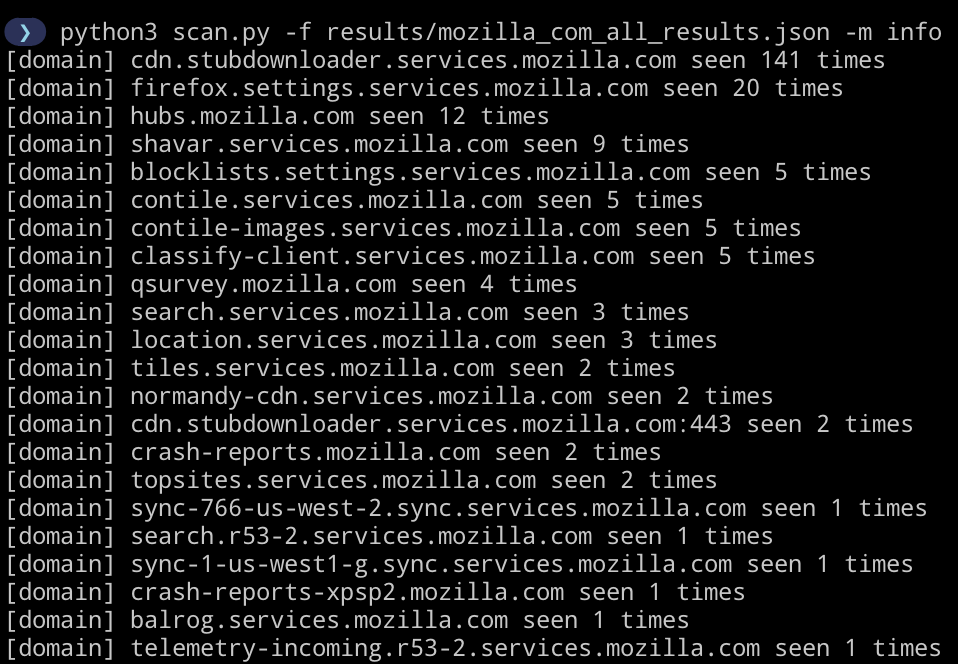
-m info
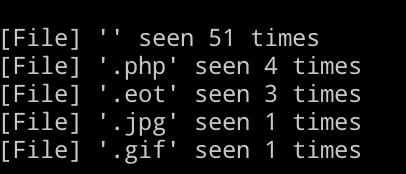
Similarly info mode can be used to return a count of each extension and subdomain within the results.
Extensions:
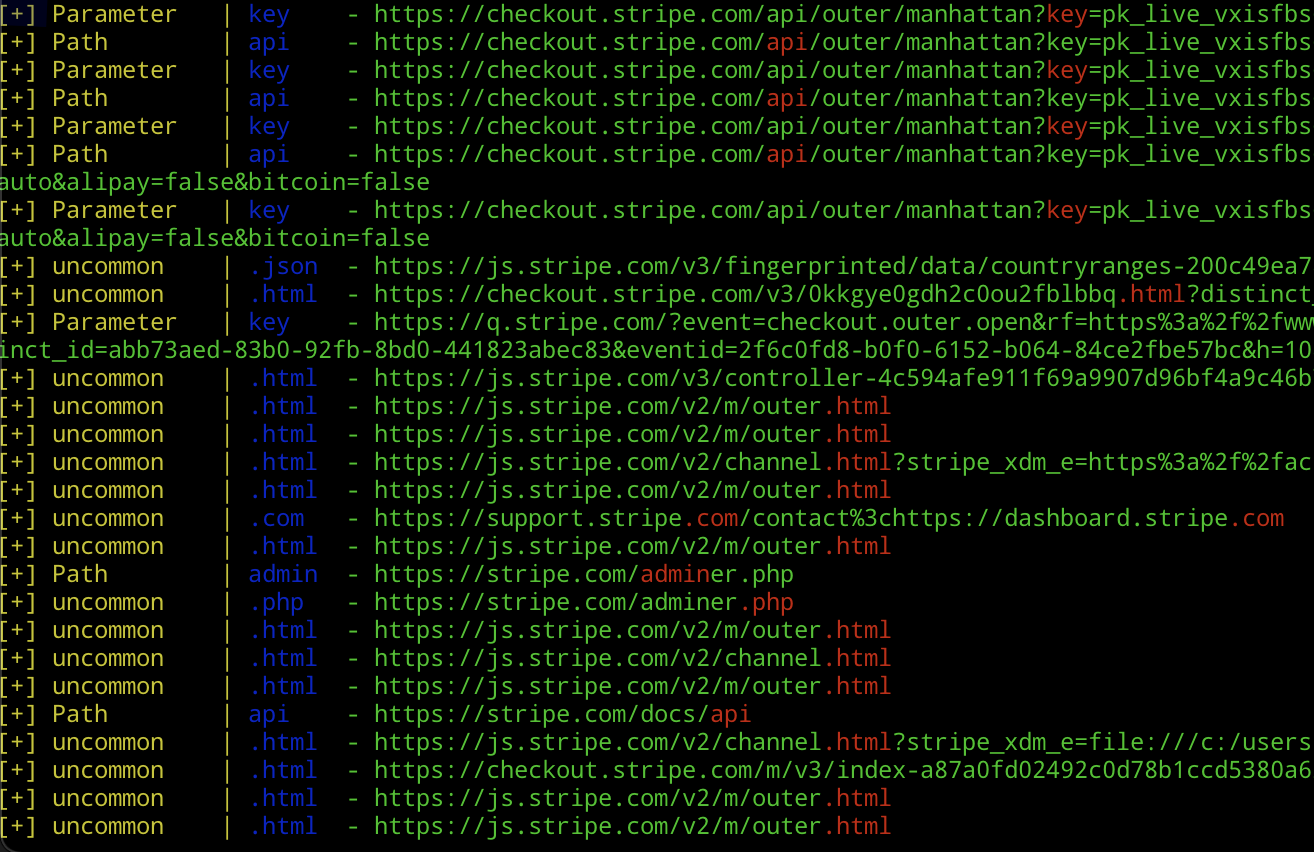
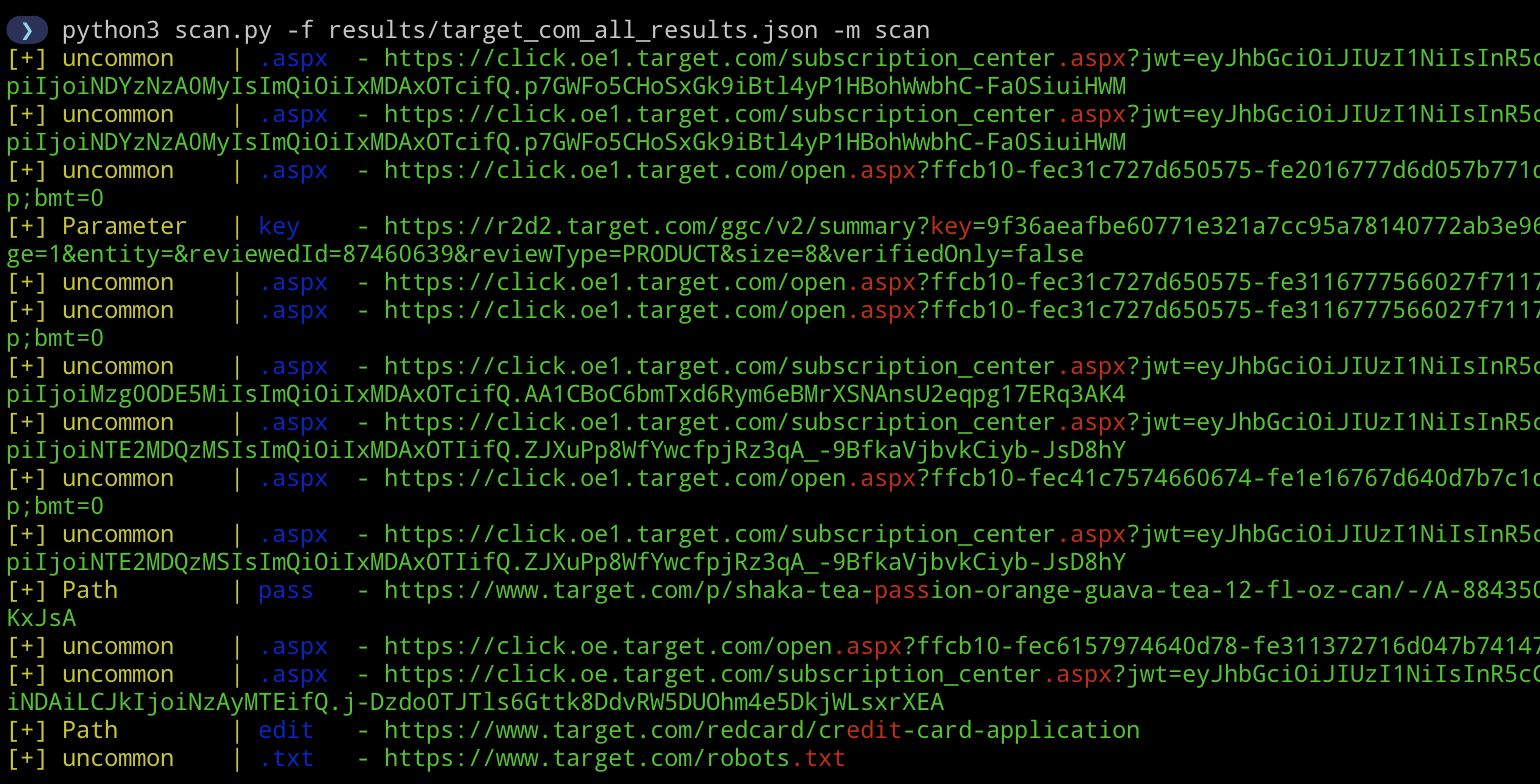
-m scan
Executes a rudimentary search for notable words and file extensions evident within the URLs. Depending on the volume of results from ‘info’ mode, you might want to tailor this. Adjustments can be made directly in scan.py.
The list of extensions and words can be modified directly within scan.py:
...
from collections import Counter
#Any changes to these two lists
common_extensions = ['','.js','.png','.gif','.jpeg','.jpg']
interesting_words = ['sql','api','swagger','tomcat','edit','upload','admin','password','uname','git','pass','username','credentials','user','debug','servlet','key','token']And you know it’s legit because of the green text ;)
Wordlist
After running this script against a large number of domains with public bounty programs, I compiled a somewhat decent subdomain wordlist (119K). It’s available for download at: https://github.com/Moopinger/wordlists/tree/main
Data Removal
If you find information you would like removed from urlscan.io, you can flag it as sensitive on their site.